Crawling data adalah proses fundamental yang menentukan apakah website Anda bisa ditemukan di Google atau tidak. Tanpa proses ini, mesin pencari tidak akan tahu bahwa halaman Anda ada di internet. Menurut data Cloudflare (2025), traffic crawler dari Googlebot meningkat 96% dalam satu tahun terakhir, sementara AI crawler seperti GPTBot tumbuh 305%. Artinya, memahami cara kerja crawling data bukan lagi sekadar teori, melainkan kebutuhan praktis bagi siapa saja yang mengelola website.
Kami di Creativism sudah menangani puluhan proyek SEO, dan dari pengalaman itu, kami menemukan bahwa banyak pemilik website yang baru sadar pentingnya crawling setelah halaman mereka tidak muncul di Google berbulan-bulan. Padahal, masalahnya sering kali sederhana: Googlebot tidak bisa mengakses halaman tersebut.
Ilustrasi proses crawling data: web crawler menelusuri jaringan halaman website dan menyimpan informasi ke database indeks mesin pencari
Crawling data adalah proses di mana mesin pencari mengirimkan program otomatis yang disebut web crawler (atau spider, bot) untuk menelusuri, membaca, dan mengumpulkan informasi dari halaman-halaman website di internet. Program ini bekerja seperti pustakawan digital yang mengunjungi setiap “rak buku” di internet untuk mencatat apa saja yang tersedia.
Menurut dokumentasi resmi Google Search Central, Google menggunakan crawler bernama Googlebot untuk menemukan dan memperbarui konten di internet. Crawler ini mengikuti tautan (link) dari satu halaman ke halaman lain, membaca konten di setiap halaman yang dikunjungi, lalu mengirimkan informasi tersebut ke database Google untuk diindeks.
Jadi intinya, crawling adalah langkah pertama sebelum halaman website bisa muncul di hasil pencarian. Urutannya begini: crawling (ditemukan) lalu indexing (disimpan di database) lalu ranking (ditampilkan di hasil pencarian). Jika halaman Anda gagal di tahap crawling, halaman tersebut tidak akan pernah sampai ke tahap indexing dan ranking.
Pro Tip: Cek Status Crawling Website Anda
Cara tercepat mengetahui apakah halaman Anda sudah di-crawl adalah dengan mengetik site:domainanda.com di Google. Jika halaman tidak muncul, kemungkinan besar ada masalah crawling. Untuk analisis lebih detail, gunakan laporan Crawl Stats di Google Search Console.
Yang jarang dibahas oleh artikel lain: crawling data bukan hanya tentang Googlebot. Di era AI, website Anda juga di-crawl oleh bot dari OpenAI (GPTBot), Anthropic (ClaudeBot), Perplexity, dan puluhan bot lainnya. Menurut laporan Cloudflare (Juli 2025), hampir 50% dari seluruh traffic internet sekarang berasal dari bot, bukan manusia.
Untuk memahami crawling data secara menyeluruh, Anda perlu tahu mekanisme di balik layar. Proses ini tidak sesederhana “bot mengunjungi website.” Ada arsitektur teknis yang cukup kompleks di belakangnya.
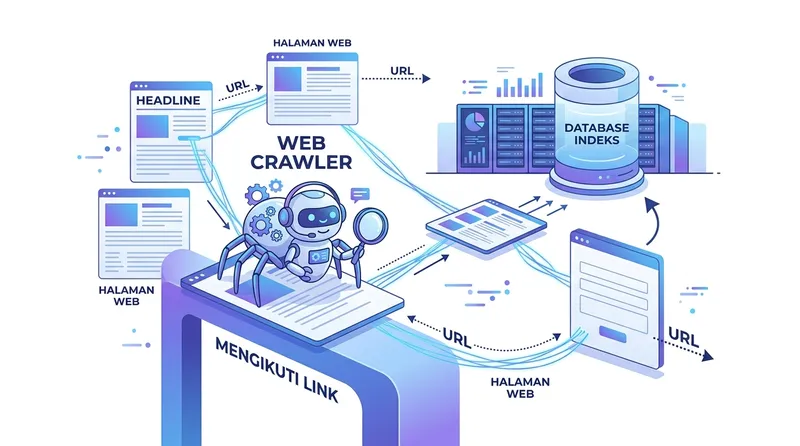
Diagram alur kerja web crawler: bot menelusuri halaman, mengikuti tautan, dan menyimpan data ke database indeks mesin pencari
Berikut tahapan cara kerja crawling data yang dilakukan mesin pencari:
Crawler memulai dari daftar URL yang sudah diketahui sebelumnya, yang disebut seed URL. Daftar ini bisa berasal dari sitemap XML yang Anda kirimkan ke Google Search Console, halaman yang sudah pernah diindeks, atau link dari website lain yang mengarah ke website Anda (backlink).
Setelah mengakses URL, crawler mengunduh konten halaman tersebut, termasuk teks, gambar, video, metadata, dan elemen HTML lainnya. Informasi ini dikirimkan ke server mesin pencari untuk diproses lebih lanjut.
Di setiap halaman yang dikunjungi, crawler akan menemukan semua tautan (hyperlink) yang ada. Tautan-tautan baru ini masuk ke antrian URL (disebut URL frontier) untuk dikunjungi berikutnya. Inilah alasan mengapa internal linking sangat penting: semakin banyak link yang mengarah ke suatu halaman, semakin besar kemungkinan halaman tersebut ditemukan crawler.
Data yang dikumpulkan crawler dikirim ke sistem indexing mesin pencari. Di tahap ini, mesin pencari menganalisis konten halaman, menentukan relevansinya terhadap berbagai kata kunci, dan menyimpannya di database indeks yang sangat besar.
Crawler tidak berhenti setelah mengunjungi halaman sekali. Menurut dokumentasi Google tentang crawl budget, Googlebot secara rutin mengunjungi ulang halaman yang sudah diindeks untuk memperbarui informasinya. Frekuensi kunjungan ulang ini tergantung pada seberapa sering konten berubah dan seberapa populer halaman tersebut.
Dari pengalaman kami menangani proyek SEO di Creativism, halaman yang diperbarui secara rutin (misalnya artikel yang di-update setiap bulan) cenderung di-crawl lebih sering dibanding halaman statis yang tidak pernah berubah.
Tidak semua crawler itu sama. Setiap mesin pencari dan platform memiliki crawler sendiri dengan tujuan dan perilaku yang berbeda. Memahami jenis-jenis ini penting agar Anda tahu siapa saja yang mengakses website Anda.
Data pangsa crawler berdasarkan laporan Cloudflare (Mei 2025)
Yang menarik, dan ini jarang dibahas oleh artikel-artikel kompetitor: lanskap crawling sudah berubah drastis sejak munculnya AI generatif. Dulu, Anda hanya perlu peduli tentang Googlebot dan Bingbot. Sekarang, ada puluhan AI crawler yang juga mengonsumsi bandwidth server Anda. Dari pengalaman kami mengaudit beberapa website klien, kami menemukan bahwa AI bot bisa mengonsumsi hingga 30-40% dari total request server.
Key Takeaway: Crawler Bukan Hanya Googlebot
Jika Anda mengelola website dengan traffic tinggi, pertimbangkan untuk mengatur file robots.txt agar mengontrol akses AI crawler. Biarkan search crawler (Googlebot, Bingbot) tetap mengakses, tapi batasi AI training bot jika diperlukan.
Crawl budget adalah jumlah URL yang bersedia dan mampu di-crawl Googlebot di website Anda dalam jangka waktu tertentu. Menurut Google Search Central, crawl budget ditentukan oleh dua faktor utama: crawl capacity limit (seberapa cepat server Anda bisa merespons) dan crawl demand (seberapa besar keinginan Google untuk meng-crawl konten Anda).
Jujur saja, tidak semua website perlu mengkhawatirkan crawl budget. Google sendiri menyatakan bahwa hanya tiga jenis website yang perlu aktif mengelola crawl budget:
Tapi kenyataannya, dari pengalaman kami menangani klien SEO, bahkan website dengan beberapa ratus halaman pun bisa mengalami masalah crawl budget jika ada banyak halaman duplikat, redirect chain, atau error 404 yang menghabiskan “jatah” crawling.
Benchmark: Target Performa Server
Server response time ideal untuk crawling adalah di bawah 500ms (di bawah 200ms untuk performa optimal). Jika server Anda merespons lebih lambat dari itu, Google akan mengurangi frekuensi crawling secara otomatis.
Yang sering terlewat: crawl budget sekarang bukan hanya soal Googlebot. Menurut Search Engine Land (2024), AI crawler yang terus bertambah juga mengonsumsi bandwidth server yang sama. Artinya, server yang dulu mampu menangani Googlebot dengan nyaman, sekarang mungkin kewalahan karena beban bot secara keseluruhan hampir dua kali lipat.
Ada beberapa faktor kunci yang menentukan seberapa efisien crawler bisa menjelajahi website Anda. Memahami faktor-faktor ini akan membantu Anda mengoptimalkan website agar lebih mudah di-crawl.
Internal link adalah jalur yang diikuti crawler untuk berpindah dari satu halaman ke halaman lain di website Anda. Halaman tanpa internal link (disebut orphan page) sangat sulit ditemukan crawler. Dari audit teknis SEO yang kami lakukan di Creativism, orphan page adalah salah satu penyebab paling umum halaman gagal terindeks.
Baca Juga: Panduan Lengkap Cara Riset Keyword untuk SEO
Sitemap XML adalah peta yang Anda berikan kepada mesin pencari, berisi daftar semua halaman penting di website. Menurut Google, menjaga sitemap tetap up-to-date dan menyertakan tag <lastmod> membantu Google memahami halaman mana yang perlu di-crawl ulang.
File robots.txt memberi instruksi kepada crawler tentang halaman mana yang boleh dan tidak boleh diakses. Kesalahan konfigurasi robots.txt bisa berakibat fatal, misalnya secara tidak sengaja memblokir Googlebot dari mengakses halaman penting.
Server yang lambat merespons akan membuat Google mengurangi frekuensi crawling. Ini bukan teori: kami pernah menangani satu klien yang server-nya sering timeout, dan Google Search Console menunjukkan penurunan crawl rate hingga 60% dibanding bulan sebelumnya.
Google menilai kualitas konten website secara keseluruhan saat menentukan crawl demand. Website dengan banyak konten berkualitas rendah, duplikat, atau halaman spam akan mendapat “jatah” crawling lebih sedikit. Sebaliknya, website dengan konten original dan bermanfaat akan di-crawl lebih sering.
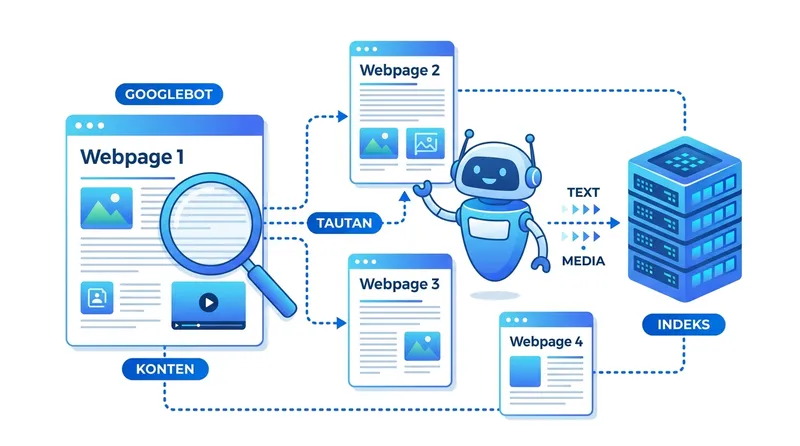
Proses Googlebot menelusuri halaman web: mengunjungi URL, membaca konten, mengikuti tautan, lalu menyimpan data ke indeks
Banyak orang mencampuradukkan istilah crawling data dan web scraping. Memang terdengar mirip, tapi keduanya punya tujuan dan mekanisme yang berbeda. Berikut perbandingan lengkapnya:
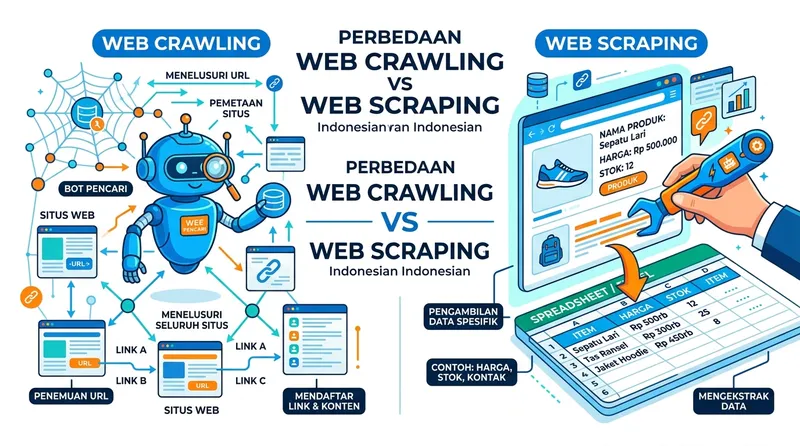
Infografis perbedaan web crawling (menelusuri URL) dan web scraping (mengekstrak data spesifik)
Menurut kami, kebingungan antara kedua istilah ini wajar karena dalam praktiknya, scraping sering memerlukan crawling terlebih dahulu. Tapi dari perspektif SEO, yang perlu Anda pahami adalah crawling: proses yang dilakukan mesin pencari untuk menemukan halaman Anda.
Mengetahui apakah website Anda sudah di-crawl dengan benar adalah langkah penting dalam audit SEO teknis. Berikut beberapa cara yang kami rekomendasikan:
Ini adalah tool gratis paling andal untuk memantau aktivitas crawling. Di menu Settings > Crawl Stats, Anda bisa melihat:
Bagi rata total crawl request dengan 90, dan Anda akan mendapatkan rata-rata harian crawl budget website Anda.
Ketik site:domainanda.com di Google untuk melihat berapa halaman yang sudah terindeks. Jika jumlahnya jauh lebih sedikit dari total halaman di website Anda, ada kemungkinan masalah crawling.
Di Google Search Console, masukkan URL spesifik ke URL Inspection Tool. Anda akan mendapatkan informasi apakah halaman tersebut sudah di-crawl, kapan terakhir di-crawl, dan apakah ada masalah yang mencegah indexing.
Ini metode paling detail tapi juga paling teknis. Dengan menganalisis server access log, Anda bisa melihat persis URL mana yang diakses Googlebot, berapa sering, dan status code apa yang dikembalikan. Menurut pengalaman kami, log file analysis sering mengungkap masalah yang tidak terlihat di Search Console.

Dashboard audit teknis SEO menampilkan status crawl, sitemap, robots.txt, dan ketersediaan indeks
Setelah memahami apa itu crawling dan cara kerjanya, langkah selanjutnya adalah mengoptimalkan website agar proses crawling berjalan efisien. Berikut strategi yang sudah terbukti berhasil dari proyek-proyek SEO yang kami tangani di Creativism:
Pastikan setiap halaman penting memiliki minimal 3-5 internal link yang mengarah ke sana. Gunakan anchor text yang bervariasi dan deskriptif. Hindari orphan page, yaitu halaman yang tidak memiliki satu pun internal link. Pelajari lebih lanjut tentang istilah-istilah penting dalam digital marketing yang terkait dengan optimasi ini.
Pastikan sitemap XML Anda selalu up-to-date. Hapus URL yang sudah tidak relevan (redirect, 404) dari sitemap, dan tambahkan URL baru segera setelah dipublikasikan.
Gunakan robots.txt untuk memblokir halaman yang tidak perlu diindeks (halaman admin, parameter URL, halaman duplikat) agar crawler tidak membuang waktu di halaman tersebut.
Investasikan pada hosting berkualitas dan optimasi server. Target waktu respons di bawah 200ms. Gunakan CDN (Content Delivery Network) untuk mempercepat pengiriman konten ke crawler.
Redirect chain (A redirect ke B, B redirect ke C) membuang crawl budget. Setiap redirect chain harus dipangkas menjadi satu redirect langsung. Halaman error 404 dan soft 404 juga harus dibersihkan karena terus di-crawl tanpa memberikan nilai.
Konten duplikat membuat crawler membuang waktu di halaman yang isinya sama. Gunakan tag canonical untuk menunjukkan versi utama dari setiap halaman. Ini membantu Google memfokuskan crawling pada konten unik.
Pro Tip: Audit Crawling Secara Berkala
Jadwalkan audit crawling minimal setiap 3 bulan. Cek Crawl Stats di Search Console, analisis halaman “Discovered – currently not indexed”, dan pastikan tidak ada resource penting yang terblokir di robots.txt. Jika Anda butuh bantuan profesional, tim SEO kami bisa membantu.
Dari pengalaman kami menangani berbagai proyek SEO, berikut adalah masalah crawling paling umum beserta cara mengatasinya:
Tapi jujur, masalah yang paling sering kami temui bukan teknis yang rumit. Justru hal-hal sederhana seperti lupa menghapus tag noindex setelah migrasi dari staging ke production, atau robots.txt yang masih memblokir seluruh website karena copy-paste dari environment development. Sederhana, tapi dampaknya bisa membuat website menghilang dari Google selama berminggu-minggu.
Lanskap crawling data sedang mengalami perubahan besar yang perlu Anda ketahui. Ini bukan sekadar teori futuristik, melainkan perubahan yang sudah terjadi sekarang.
Menurut riset Cloudflare (Juli 2025), berikut beberapa tren utama:
Apa implikasinya bagi pemilik website? Pertama, server Anda harus siap menangani beban bot yang jauh lebih besar. Kedua, Anda perlu strategi untuk mengelola akses AI crawler. Memahami funnel marketing dalam konteks AI search juga menjadi semakin relevan karena AI mengubah cara pengguna menemukan dan mengonsumsi konten.
Yang jarang dibahas: tidak semua AI crawler itu sama dari segi etika. Beberapa crawler, seperti OAI-SearchBot (ChatGPT Search), berfungsi mirip Googlebot karena mengambil konten untuk ditampilkan sebagai hasil pencarian. Sementara GPTBot mengambil konten untuk melatih model AI, yang berarti konten Anda digunakan tanpa atribusi langsung. Anda berhak memblokir yang kedua tanpa memengaruhi visibilitas di AI search.
Selain Google Search Console, ada beberapa tools yang bisa membantu Anda menganalisis dan mengoptimalkan proses crawling:
Tool desktop yang bisa meng-crawl website Anda layaknya Googlebot. Versi gratis bisa crawl hingga 500 URL. Sangat berguna untuk menemukan broken link, redirect chain, halaman tanpa meta tag, dan masalah teknis lainnya.
Selain menganalisis profil backlink, Ahrefs juga memiliki fitur site audit yang melakukan crawling dan menampilkan masalah teknis SEO termasuk status crawlability setiap halaman.
Gratis dan langsung dari Google. Fitur Crawl Stats dan URL Inspection memberikan data paling akurat tentang bagaimana Googlebot berinteraksi dengan website Anda.
Menawarkan audit teknis komprehensif termasuk analisis crawlability, indexability, dan performa website. Cocok untuk website skala menengah hingga besar.
Tools seperti Screaming Frog Log File Analyser atau JetOctopus bisa membantu menganalisis server log untuk melihat perilaku crawler secara real-time.
Crawling data adalah proses di mana mesin pencari menggunakan program otomatis (web crawler/bot) untuk menelusuri, membaca, dan mengumpulkan informasi dari halaman-halaman website di internet. Proses ini menjadi langkah pertama agar halaman website bisa muncul di hasil pencarian Google.
Crawling adalah proses penemuan halaman, sedangkan indexing adalah proses penyimpanan dan pengategorian halaman yang sudah ditemukan ke dalam database mesin pencari. Halaman harus di-crawl dulu sebelum bisa diindeks. Tidak semua halaman yang di-crawl akan diindeks, tergantung kualitas kontennya.
Bervariasi, bisa mulai dari beberapa jam hingga beberapa minggu. Website dengan otoritas tinggi dan update rutin biasanya di-crawl lebih cepat. Anda bisa mempercepat proses ini dengan mengirimkan URL ke Google Search Console menggunakan fitur URL Inspection dan Request Indexing.
Pada umumnya tidak, karena Google mengatur crawl capacity limit agar tidak membebani server. Namun untuk website dengan server terbatas, traffic crawler yang tinggi (terutama dari AI bot) bisa memengaruhi performa. Solusinya adalah meningkatkan kapasitas server atau mengatur akses bot melalui robots.txt.
Crawl budget adalah jumlah URL yang bersedia dan mampu di-crawl Google di website Anda dalam jangka waktu tertentu. Menurut Google, hanya website besar (1 juta+ halaman), website dengan konten yang sering berubah, atau website dengan banyak halaman “Discovered – currently not indexed” yang perlu aktif mengelolanya.
Cara termudah adalah menggunakan fitur URL Inspection di Google Search Console. Masukkan URL halaman, dan Google akan menampilkan informasi apakah halaman sudah di-crawl, kapan terakhir dikunjungi, dan apakah sudah masuk indeks. Alternatif cepat: ketik “site:URL_halaman” di Google.
Tidak berbahaya secara langsung, tapi bisa mengonsumsi bandwidth server. AI crawler mengambil konten untuk melatih model AI atau menampilkan hasil pencarian AI. Anda bisa mengontrol akses mereka melalui robots.txt. Untuk AI search crawler (OAI-SearchBot), sebaiknya tetap diizinkan agar konten Anda muncul di hasil AI search.
Crawling data adalah fondasi dari seluruh proses SEO. Tanpa crawling yang sukses, halaman website Anda tidak akan pernah muncul di hasil pencarian Google, tidak peduli seberapa bagus kontennya. Memahami cara kerja crawler, mengelola crawl budget, dan mengoptimalkan faktor-faktor teknis adalah investasi yang akan memberikan hasil jangka panjang.
Di era AI, lanskap crawling menjadi semakin kompleks dengan munculnya puluhan bot baru yang semuanya mengakses website Anda. Pemilik website perlu proaktif dalam mengelola akses bot dan memastikan server mampu menangani beban yang terus bertambah.
Jika Anda membutuhkan bantuan untuk mengaudit dan mengoptimalkan crawling website Anda, layanan SEO profesional dari Creativism siap membantu. Kami sudah berpengalaman menangani berbagai kasus teknis SEO dan bisa memastikan website Anda terindeks dengan optimal.

