
Apa itu Web Crawling – Ketika Anda mempelajari SEO Marketing, maka Anda akan temukan berbagai istilah baru yang ada di dalamnya. Salah satunya adalah web crawling. Bagi profesional, istilah ini jelas bukanlah istilah yang awam didengar. Lain halnya jika arti dari web crawling ini ditanyakan kepada mereka yang masih pemula di bidang SEO marketing.
Lantas apakah yang dimaksud dengan web crawling?. Berikut ini penjelasan lengkapnya untuk Anda;
Dikutip dari Totally Tech, Web Crawling adalah proses search engine dalam menemukan konten yang di-update pada sebuah situs. Definisi yang hampir mirip juga diberikan oleh Moz. Menurut Moz, web crawling adalah proses pengiriman robot spider, yang robot ini berfungsi temukan konten baru yang sudah diberi update.
Adapun konten tersebut bisa saja berupa gambar, video, dokumen ataupun bentuk tampilan dari halaman website tu sendiri.
Konsep kerjanya mirip dengan seekor laba-laba dengan jaringnya. Laba-laba akan bergerak ke sisi lain dari jaringnya, apabila terdapat mangsa yang terperangkap. Melalui getaran jaring yang diterima (link), laba-laba kemudian mendatangi sumber getaran tersebut (konten) untuk kemudian dimasukkan dalam gumpalan jaring (proses indexing).

Sumber: Searchenginejournal.com
Secara garis besar, MinTiv telah menerangkan kepada Anda cara kerja web crawling dengan mudah memanfaatkan analogi laba-laba. Ya, secara umum Anda bisa memahami bahwa web crawling memiliki cara kerja seperti itu.
Web crawler akan mengunjungi sebuah situs atau link baru pada halaman tertentu. Link tersebut akan dicatat oleh web crawler dan kemudian dimasukkan ke dalam database index Google.
Baca Juga: Manfaat Menjalankan SEO Marketing
Di sini, web crawler hanya bertugas untuk mengumpulkan link yang ditemukan saja. Terlebih pada link yang memang diberikan aksesnya untuk publik. Web crawler tidak akan bekerja pada link yang aksesnya terbatas atau private.
Pengaturan link atau konten yang diberi privasi ini bisa Anda terapkan apabila Anda sudah memahami konsep Robots.txt. Anda bisa lengkap tentang Robots.txt pada link artikel di bawah ini;
Baca Juga: Apa itu Robots.txt dan Manfaatnya untuk SEO Website?
Setelah Anda mengetahui definisi daripada web crawling beserta dengan cara kerjanya, Anda pasti mulai bertanya-tanya tentang fungsi sebenarnya dari tools Google ini. Fungsi dari web crawling ini sendiri dapat kita pahami dalam 3 bagian utama. 3 bagian tersebut adalah;
Yang pertama adalah sebagai penyedia data untuk keperluan analisis. Perlu diketahui bahwa Web Crawler adalah penyedia data utama untuk tools analisis website seperti Google Search Console dan juga Screaming Frog SEO. Tanpa adanya web crawler kedua tools ini tidak akan mampu bekerja secara maksimal.
Data yang dihasilkan oleh tools analisis memanfaatkan data yang dibawakan oleh web crawler tentunya akan jauh lebih akurat.
Yang kedua, adalah web crawler dapat berfungsi sebagai pembanding harga produk di Internet. Data yang didapatkan oleh web crawler ini sangatlah akurat memanfaatkan data-data yang ada di dalam database index sebelumnya.
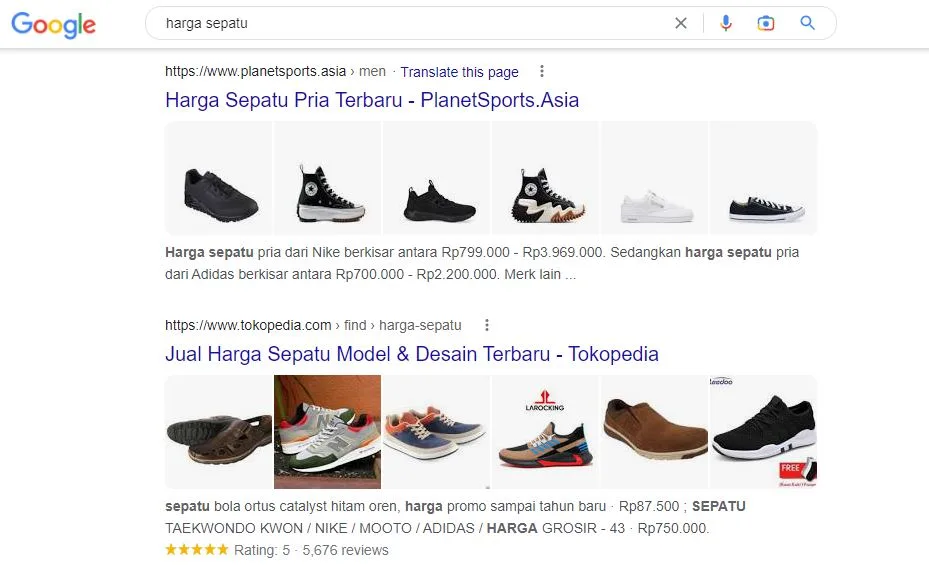
Sumber: Google
Fungsi yang ketiga adalah memudahkan Anda untuk melihat data-data secara statistik. Salah satu contohnya ketika Anda mengetikkan keyword Statistik Covid-19. Google akan menampilkan hasil keyword tersebut dengan pencarian seperti pada gambar di bawah ini;

Sumber: Google
Contoh lainnya, saat Anda menggunakan Google News untuk mencari berita, maka berita yang muncul berasal dari website yang menggunakan sitemap khusus.
Ada banyak jenis daripada web crawling. Di sini, MinTiv akan menjelaskan 5 jenis web crawling yang memang sering Anda jumpai. 5 web crawling tersebut adalah news, social media, image, video, dan juga email crawling. Berikut masing-masing penjelasan kelima jenis web crawling tersebut;
Yang pertama adalah news crawling. Konten yang masuk ke dalam crawling adalah hasil konten terbaru yang sudah menerapkan RSS feeds. Di dalam konten RSS feeds inilah ada beberapa hal yang dipindai oleh web crawler seperti tanggal penerbitan, nama penulis, paragraf utama, judul utama, dan bahasa dari konten berita tersebut.
Selanjutnya adalah social media crawling. Contoh sosial media yang menerapkan crawling ini adalah Twitter dan juga Pinterest. Adapun izin yang diberikan untuk social media crawling adalah halaman yang di dalamnya pengguna tidak memberikan informasi pribadi apapun.
Perlu diingat, tidak semua sosial media mengizinkan web crawling di dalam sistemnya.
Selanjutnya adalah video crawling. Jenis web crawling ini akan berfungsi apabila konten Anda memiliki data dari konten sematan dari Youtube, Soundcloud, dan video lainnya.
Jenis web crawling yang satu ini berfungsi membantu pengguna dalam menemukan gambar yang relevan sesuai kata kunci yang diberikan.
Hampir mirip dengan social media crawling, hanya saja lingkup pengerjaannya dilakukan pada area email.
Contoh yang pertama adalah Googlebot. Googlebot menjadi web crawler paling populer di kalangan pebisnis yang menerapkan SEO marketing. Selain karena nama besar Google, Googlebot memang terbukti memudahkan pebisnis online dalam mengatur indexing website bisnis.
Web crawler yang satu ini merujuk pada dua jenis web crawler, yaitu desktop crawler dan mobile crawler.
Kedua, adalah HTTrack. Sebuah web crawler yang bersifat open source dan dapat dilihat secara online. Anda dapat memperolehnya melalui situs World Wide Web.
Sama dengan HTTrack. Hanya saja Cyotek Webcopy ini memiliki kelebihan dengan memungkinkan penggunanya memilih bagian yang ingin download. Semisal foto tertentu pada website tidak ikut dalam proses download.
Yang terakhir, adalah Webhose. Web crawler yang dapat mengubah konten website yang tidak terstruktur menjadi data feeds yang dapat dibaca oleh mesin. Data feeds yang dimaksud mencakupi banyak sumber data, mulai data dari diskusi online, situs berita, dan lainnya.
Definisi web crawling sudah terjawab pada pada penjelasan sebelumnya. Untuk pertanyaan kedua?.
Jawaban sebenar dari pertanyaan kedua ini sudah tersampaikan secara tersifat pada penjelasan MinTiv sebelumnya. Web crawler berfungsi untuk membantu konten website Anda mendapatkan indexing untuk kemudian bersaing kualitas dengan konten-konten website lainnya.
Baca Juga: Faktor Faktor Penting dalam SEO Website
Tanpanya, konten website Anda tidak mungkin bisa ditemukan pada halaman pencarian Google. Tapi ingat, web crawler bukan satu-satunya faktor penting peningkat SEO website Anda.
Apabila Anda berminat untuk mendapatkan Jasa SEO Web Profesional dari SEO Agency Terpercaya, hubungi Creativism.id.
Creativism menyediakan layanan Digital Marketing untuk perorangan, UMKM, UKM, hingga perusahaan besar yang mencari partner untuk menghandle social media, website, SEO, dan menyediakan seluruh kebutuhan promosi hingga IT Solution untuk bisnis Anda. Hubungi mereka di nomor 6281 22222 7920.



[…] Baca Juga: Apa itu Web Crawling dalam SEO Marketing? […]
[…] Baca Juga: Apa itu Web Crawler dan Fungsinya dalam Web Marketing? […]
[…] memasukan gambar pada konten yang relevan tentunya akan menambah nilai baik website Anda di mata crawler Google. Perlu diketahui juga bahwa penggunaan gambar yang tepat dan relevan akan memudahkan konten […]